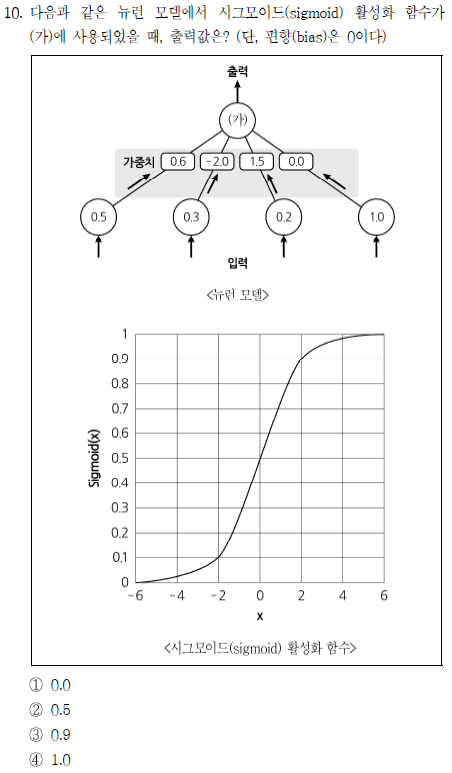
인공 신경망에서 활성화 함수에 대한 가중치 계산만 할 수 있으면 풀 수 있는 문제다. (0.5×0.6)+(-2.0×0.3)+(1.5×0.2)=0이므로 시그모이드 함수에 0을 입력한 값이 출력이다. 따라서 정답은 ②

간단한 CNN 구조에 대해 묻고 있다. 그렇게 어려운 문제는 아니다.
① 이미지 분류는 CNN의 대표적인 용례다.
②~③ CNN은 크게 feature learning 영역과 classification 영역으로 나눌 수 있는데, 언급된 convolution과 pooling은 feature learning 영역에 속한다. 즉, 주어진 이미지의 특성을 feature extraction을 통해 학습하는 과정이다. 참고로 classification 영역은 fully connected, flatten, softmax 함수 등으로 구성되는데, 이는 어디까지나(feature learning 영역 포함) 선택의 영역으로, 모든 CNN 구조가 다 이런 식의 구조로 이뤄져있다는 것은 아니다.
④ dropout 기법은 overfitting을 막기 위한 대표적인 기법으로, 학습 과정에서 일부 노드를 일부러 학습에서 제외함으로써 건전한 임의성을 부여하는 방법이다. overfitting 자체가 주어진 데이터의 패턴을 과도하게 학습하는 것이기 때문에 과도하게 학습하지 않도록 방해하는 역할이라고 보면 된다.

개인적으로 정말 놀란 문제다. 물론 답을 찾는 것은 매우 쉽지만 선지의 난이도는 꽤 높은 편이다. 작정하고 문제의 난이도까지 어렵게 만들었으면.. 아마 제대로 알고 맞춘 사람이 거의 없지 않았을까 싶다.
AutoEncoder는 기본적으로 생성 모델이며, 입력 데이터와 유사한 패턴을 생성하는 역할을 한다. 이미지 생성에도 쓰일 수 있지만 Augmentation(데이터 증강)에도 쓰일 수 있고 자연어 심지어 정형 데이터에도 활용 가능하다. AutoEncoder는 encoder와 decoder로 구성되며 encoder는 주어진 데이터의 패턴을 학습하여 latent variable을 생성하고, decoder는 latent variable을 바탕으로 새로운 데이터를 생성한다.
이렇게 생성된 새로운 데이터는 명확한 정답(label)이 있는 것이 아니기 때문에 대표적인 비지도 학습에 속하며, ①번의 특징 추출은 encoder에서 수행된다. 그리고 encoder에서 줄어든 차원이 decoder에서 회복되어 원래의 차원을 회복하므로 ③번도 맞다.
문제는 ④번 선지인데, 이걸 처음 읽은 사람은 도대체 뭔 소리인가 싶겠을 거고, 실제로도 이해하기 어려운게 맞다. 이걸 이해하려면
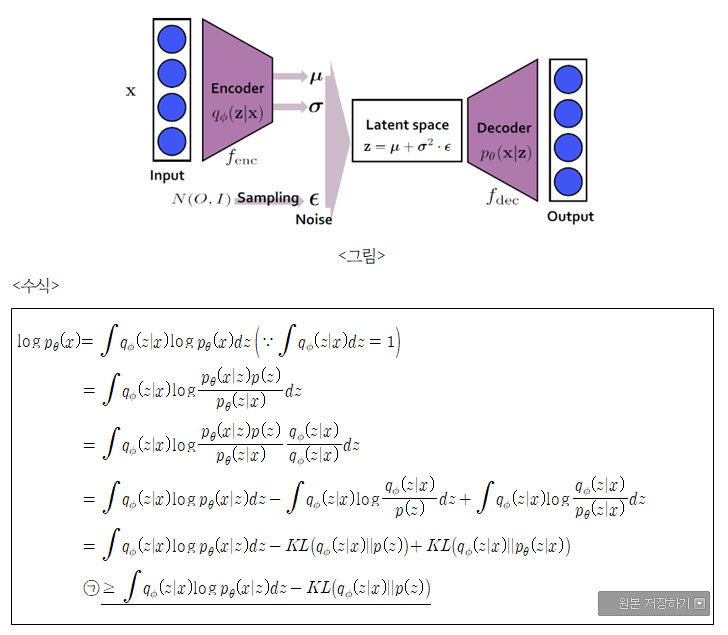
위 그림과 수식을 이해해야 한다.
사실 그림을 봤으면 알겠지만 ④번 선지는 용어를 잘못 썼다. '잠재 변수'는 AutoEncoder에 해당하는 것이고, Variational AutoEncoder(VAE)의 경우는 '잠재 공간(latent space)'를 쓰는게 맞다. 왜냐 하면 그 둘의 차이가 AE와 VAE의 결정적인 차이니까.
VAE도 기본적인 모델은 AE랑 비슷하다. Encoder가 차원 축소하고, decoder가 차원 복원하는 그런 플롯은 비슷한데, AE는 latent variable이라 해서 하나의 특정 변수로 축소한다. 그런데 AE는 latent variable에 아무런 제약을 가하지 않기 때문에 원본 데이터의 특징을 얼마나 잘 잡아냈느냐와는 무관하게 비슷하게만 생성하면 장땡인.. 그런 한계를 가지고 있다.
이런 한계를 극복하기 위해 VAE가 추가한 장치가 바로 위의 수식이다. 위 수식의 ㉠ 문장을 보면 두 항으로 구성되어 있다.
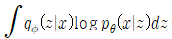
이 수식의 뜻은 encoder와 decoder에 대한 cross entropy를 나타낸 것이다. 즉, 원본 데이터를 decoder가 얼마나 비슷하게 구현했느냐를 나타내는 것으로 reconstruction error라고 부른다.
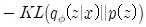
이 수식은 쿨백-라이블러 발산을 이용해 두 확률 분포 간의 차이를 나타낸 것이다. 그 두 확률 분포는 encoder와 latent space로, latent space가 최대한 차원 축소를 행하도록 하는 것이 목적으로, 앞의 항과는 달리 차이가 커지게 하는 것이 목적이기 때문에 (-) 부호를 붙인다. 이런 항을 regularization error라고 부른다.
따라서 ④번은 맞는 말이다.
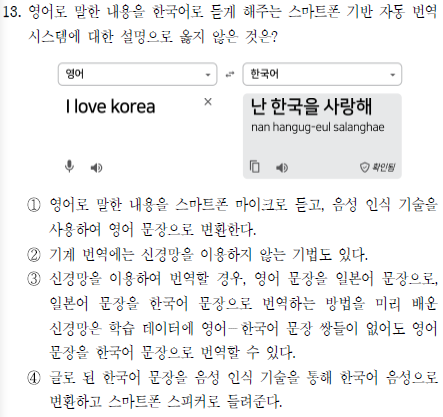
그냥 글만 잘 읽어도 해결되는 문제다. 거저 주는 문제. 정답은 ④번이고, 그 이유는 문장을 음성 인식 기술로 변환할 수는 없기 때문. 음성 인식 기술은 음성을 자연어 문장으로 변환하는 기술이다. 그런데 난 이 문제 틀림.. ㅋㅋ

5급 인공지능에서도 나온 문제다. k-means 클러스터링인데, 특히 5급 문제에서는 거리를 유클리드 거리가 아니라 맨해튼 거리로 계산하는 문제가 나왔다. 정답은 ②번.

데이터 전처리에 관한 문제다. 기계학습에 있어 전처리는 가장 중요하고 필수적인 과정이자 가장 오래 걸리는 과정이기도 하다. 모델이 요구하는 데이터 형식에 맞춰 raw data를 변환하는 과정이 완전 노가다라 단순하고 오래 걸리는 작업이다.
① missing value 처리는 말 그대로 null값들을 채워 넣는 것으로, imputation이라고도 부른다. 평균값, 중간값, 최솟값, 최댓값 등 다양한 방법이 있을 수 있다.
② one-hot encoding은 주로 자연어 embedding에도 많이 쓰이는 방법인데, 해당 값이 존재하면 1, 아니면 0을 채워넣는 방법이다. 예를 들어 "I love her." 이라는 문장이 있을 때 "I" 는 {1, 0, 0}, "love"는 {0, 1, 0}... 이런 식이다.
③ k-fold cross validation은 데이터의 수가 부족할 때 검증을 제대로 하기 위해 주어진 데이터들을 k개의 fold로 나눠서 각각에 대한 검증을 진행하는 방법이다. 자매품으로 leave-p-out cross validation도 있다. 찾아볼 사람만 찾아보는게 좋을듯.
④ SMOTE는 Synthetic Minority Over-sampling Technique의 약자다. 이름을 해석해보면 대충 유추가 가능하지만 이건 sampling 알고리즘이라기보다 augmentation 쪽에 가깝다. SMOTE는 데이터의 불균형을 해소하는 기법인데, 가장 근접한 특정 벡터와의 거리에 0~1 사이의 난수를 곱해 기존의 데이터셋에 추가하는 식이다. Over-sampling은 작은 데이터셋에서 큰 데이터셋으로 확장하는 것이다.
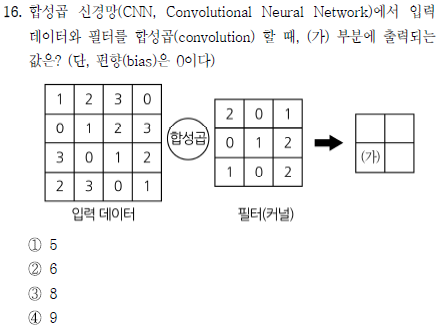
평범한 CNN 커널 계산문제다. 이 문제는 전에 지방직에서도 출제된 적이 있기 때문에 어렵지 않게 예측할 수 있는 유형의 문제였다. (가)의 값은 좌측 하단에만 커널을 적용시키면 0+0+2+0+0+2+2+0+0 =6 따라서 정답은 ②
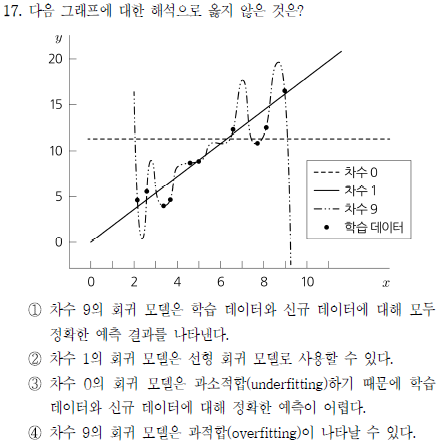
개인적으론 overfitting에 대한 문제가 1문제밖에 출제되지 않아서 좀 아쉬웠는데 이 문제가 그 문제다. 이 그래프는 초기 모델이 데이터를 학습하는 과정 전반을 나타내고 있는데, 차수 0일땐 전혀 학습이 되지 않은 경우(underfitting), 차수 1일 땐 적절한 학습된 상태, 차수 9일땐 과적합(overfitting) 상태를 나타낸다.
그래서 ①번은 틀린 설명이다. Overfitting은 학습 데이터에만 지나치게 집중하여 다른 데이터셋에 대한 패턴 파악 능력은 떨어지는 상태를 말하는 것이기 때문이다. 반대로 과소적합(underfitting)은 현재 학습 데이터에 대한 패턴도 제대로 파악되지 않은 상태를 말한다.
Overfitting에 대해서는 variance, bias와 연관시켜 시험에 출제될만 하다. 과녁에 점 찍는 그 그림을 가지고 말이다.

① Vanishing Gradient 문제는 RNN뿐만 아니라 모든 딥러닝 모델에서 나타날 수 있는 문제다. 역전파 과정에서 가중치를 업데이트하면서 활성화 함수에 대한 편미분을 계산하는데, 편미분을 매 hidden layer마다 하게 되면 결국에 값이 점점 0으로 수렴해 나중에는 가중치가 점점 업데이트되지 않는 문제를 말한다. 이 문제는 sigmoid 함수나 하이퍼볼릭 탄젠트 함수에서 두드러지는데, 실제로 도함수의 최댓값이 0.3인가 그 정도밖에 안된다.
② LSTM은 이전에 업데이트됐던 정보를 memory cell을 통해 얼만큼 저장하고 다음 cell로 전달할 것인지를 결정한다. 하지만 이후 시험의 입력값까지 반영하지는 않는다. 아니 못한다...
③ dropout은 overfitting을 방지하기 위한 대표적인 기법이다. 앞에서도 설명했듯이 일부 노드를 일부러 학습에 반영하지 않음으로써 모델이 학습 데이터를 과하게 학습하는 것을 방해하는 것이다.
④ 옳은 말이다. GRU는 LSTM보다 gate가 1개 더 적은데, 비슷한 성능을 보이거나 일부 데이터에 대해선 오히려 더 좋은 성능을 보여주기도 한다. 놀랍게도 GRU 모델은 한국인 박사가 설계한 모델..!
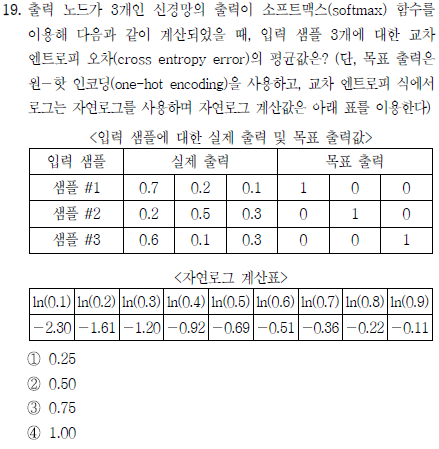
cross entropy error를 계산하는 문제다. cross entropy를 계산하는 공식은 Autoencoder 문제에서도 살짝 나왔지만
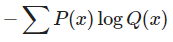
이다. 이 식을 적용해 cross entropy error의 평균을 구해보면
따라서 정답은 ③
'잡설' 카테고리의 다른 글
| 23년 5급 인공지능 해설 (1) | 2024.05.30 |
|---|---|
| 23년 7급 인공지능 기출 해설 (20~25번) (0) | 2024.05.24 |
| 23년 7급 인공지능 기출 해설 (1~9번) (0) | 2024.05.24 |
| Tchaikovsky Symphony No.5 (0) | 2023.05.11 |
| 잡담 - 로아온 윈터와 플레체 (0) | 2023.05.11 |


